
+ HARD WORK.
+ IN MOTION.
+ NOTHING WASTED.
Authentic identities for
founders building
culture-led brands.


We help founders turn momentum into iconic brands through strategy, design and focused execution.
+ SAY LESS.
+ MEAN MORE.
+ XXXL DESIGN.
Branding works best when it has direction. Without it, brands drift, iterate endlessly, and lose their edge.
Kuma helps founders define that point of view and shape it into a confident, intentional brand identity built to last.
SELECTED WORKS
INDEX.
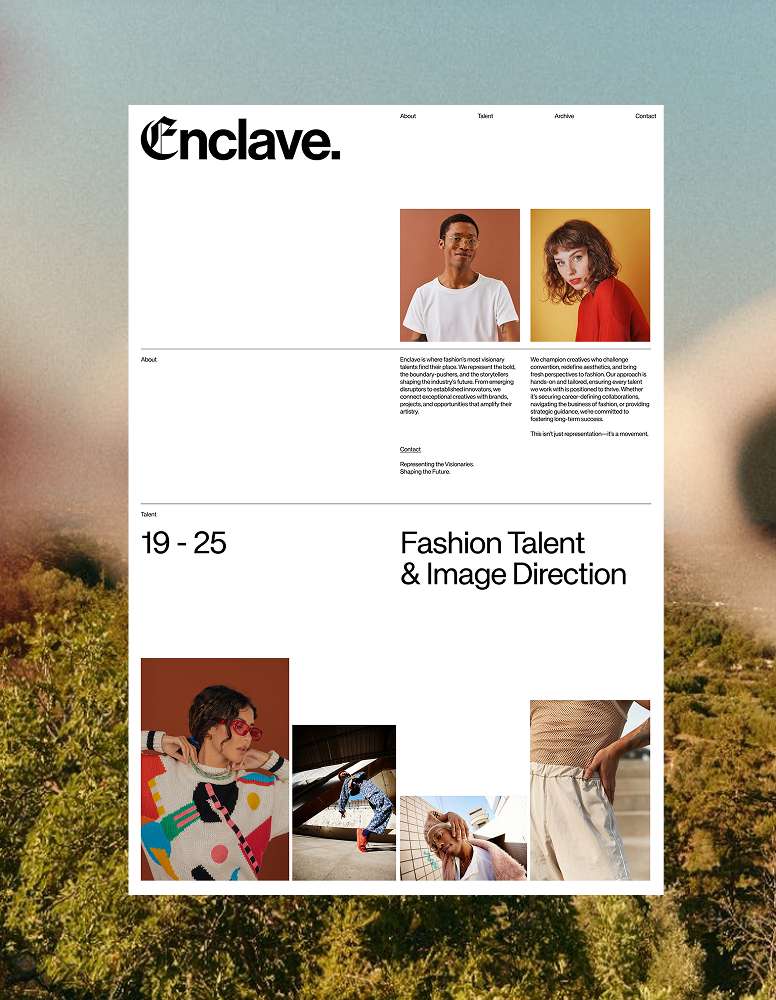

Enclave
/ FASHION
/ AGENCY
/ STUDIO
Ruger
/ HAIR
/ LIFESTYLE
/ GROOMING


Founded
/ BUSINESS
/ NEWS
/ PUBLISHING
Earth's Secret
/ HEALTH
/ NATURAL
/ WELLNESS
BENEFITS
Branding built for founders who want to move. A clear scope and a focused process, turning ideas into something real. All for £10k.
+ WELL DEFINED
+ WELL PRACTISED
+ WELL EXECUTED
1
Working brand in 2 weeks.
Focused, decisive work that results in a complete, usable brand you can put to work immediately.
2
Experienced by design
You work directly with highly experienced designers. No juniors, no hand-offs, no dilution.
3
No surprises
A clear scope and fixed fee mean you know exactly what you’re getting, with no creep or hidden extras.
Our Process
+ FEWER MOVES.
+ CLEANER FINISH.
01
SET THE
SPARK
We immerse ourselves into your world to uncover what really matters. Perspective, insight, and sharp questioning that set a clear narrative.
02
SHAPE
THE VISION
We translate insight into direction. Concepts, visual language, and a clear creative path that gives the brand its shape and voice.
03
BUILD
TO MOVE
We design and deliver the full identity, ready to use. Everything you need to launch with confidence and keep the energy going.
+ WE'VE DONE.
+ THE TIME.
We've arrived here after years of building brands across different stages, sectors, and challenges. We’ve seen what works, what doesn’t, and how to move with confidence from day one.








MOBILE
HARD WORK IN MOTION. NOTHING WASTED.
Authentic identities for founders building culture-led brands.
We help founders turn momentum into iconic brands through strategy, design and focused execution.
SAY LESS. MEAN MORE. XXXL DESIGN.
Branding works best when it has direction. Without it, brands drift, iterate endlessly, and lose their edge.
Kuma helps founders define that point of view and shape it into a confident, intentional brand identity built to last.
SELECTED WORKS
BENEFITS
Branding built for founders who want to move. A clear scope and a focused process, turning ideas into something real. All for £10k.
1
Working brand in 2 weeks.
Focused, decisive work that results in a complete, usable brand you can put to work immediately.
2
Experienced by design
You work directly with highly experienced designers. No juniors, no hand-offs, no dilution.
3
No surprises
A clear scope and fixed fee mean you know exactly what you’re getting, with no creep or hidden extras.
Our Process
01
SET THE SPARK
We immerse ourselves into your world to uncover what really matters. Perspective, insight, and sharp questioning that set a clear narrative.
02
SHAPE THE VISION
We translate insight into direction. Concepts, visual language, and a clear creative path that gives the brand its shape and voice.
03
BUILD TO MOVE
We design and deliver the full identity, ready to use. Everything you need to launch with confidence and keep the energy going.
+ WE'VE DONE THE TIME.
We've arrived here after years of building brands across different stages, sectors, and challenges. We’ve seen what works, what doesn’t, and how to move with confidence from day one.